
真实工作流,正在成为下一代训练数据
真实工作流,正在成为下一代训练数据数据市场的故事,正在进入新一轮周期。来自企业真实工作流的 Real-world Data,成为越来越多 AI Labs 争夺的新资源。比如 GitHub 就是典型的 Real-world Data,它几乎完整保留了一个问题从出现到解决的全过程。相比之下,今天绝大多数 Human Data 公司提供的,仍是人为构造的数据。
来自主题: AI技术研报
8562 点击 2026-07-24 11:00
 搜索
搜索
数据市场的故事,正在进入新一轮周期。来自企业真实工作流的 Real-world Data,成为越来越多 AI Labs 争夺的新资源。比如 GitHub 就是典型的 Real-world Data,它几乎完整保留了一个问题从出现到解决的全过程。相比之下,今天绝大多数 Human Data 公司提供的,仍是人为构造的数据。

上海人工智能实验室团队提出的Self-Harness,近期被LangChain CEO、联合创始人Harrison Chase转发,也被前OpenAI副总裁Lilian Weng收进自进化Agent相关博客。它盯上的不是换模型,而是Agent外层那套Harness。

近期,字节跳动商业化GenAI中国区负责人、原AI Lab技术负责人袁泽寰确认离职,创业方向锚定世界模型赛道,聚焦Physical AI领域的基础模型研发。

2026年4月,一位在美国AI圈极具影响力的研究者,专程来到中国,走进北京、杭州和上海的AI实验室。他密集拜访了阿里巴巴、月之暗面、智谱、清华、美团、小米、蚂蚁和零一万物等团队。回到美国后,他写了一篇名为《Notes from inside China's AI labs》(中国AI实验室内部观察随笔)的文章,在美国科技圈引发了不小讨论。

近日,上海AI Lab等团队提出了一种面向专业软件智能体的新范式——ComAct(COM-as-Action)。它的核心思想在于:不再把鼠标点击和键盘输入作为Agent的action,而是让Agent直接生成COM代码,通过软件底层对象模型操纵真实专业软件。
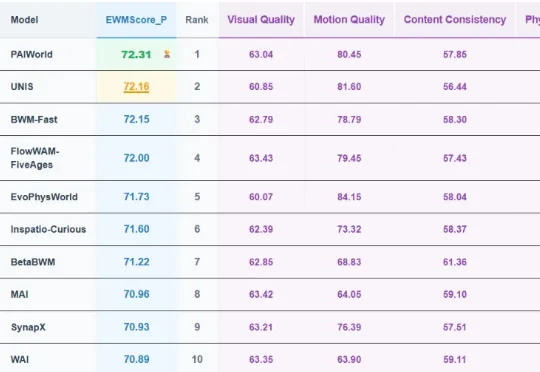
日前,世界模型国际权威榜单 WorldArena 更新排名,中国科学院工业人工智能研究所徐凯研究员带领物理智能团队(The PAI Lab)自研的世界模型 PAIWorld 登顶。WorldArena 作为目前世界模型领域最权威的评测榜单,是针对具身世界模型的全方位评价体系,涵盖视觉质量、运动质量、内容一致性、物理遵循、三维准确性及可控性六大维度

前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。
在这场日益蔓延的“Token焦虑”中,Agnes AI的举动显得格外扎眼——这家全球榜单排名第九的AI Lab宣布,自6月1日起,旗下全模态模型API无限期免费开放。Agnes AI本次开放覆盖其三款核心模型:文本模型Agnes-2.0-Flash、图像模型Agnes-Image-2.0-Flash以及视频模型Agnes-Video-V2.0。
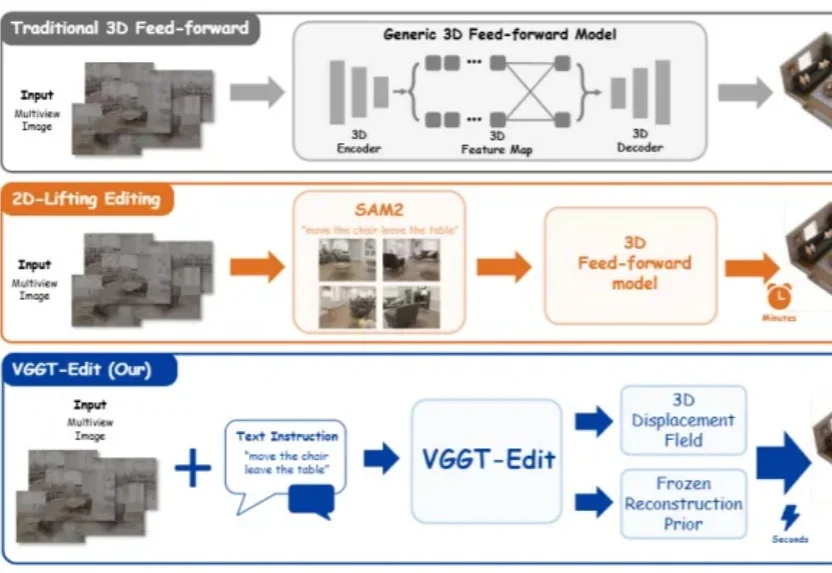
3D世界“会看”了,但还不会“改”。

随着大模型后训练(Post-training)技术的发展,强化学习(RL)在提升模型推理能力方面的表现备受瞩目。